

En la quinta versión del benchmark MLPerf Inference, publicado por MLCommos, Intel aparece como el único fabricante en reportar resultados utilizando CPUs de servidores.

La quinta edición del benchmark incorpora cuatro pruebas cable, todas pensadas para diferentes escenarios como detección 3D en el borde, redes nueronales de grafos para sistemas de recomendación o fraude:
- Llama 3.1 405B,
- Llama 2 70B Interactive,
- GNN-RGAT y
- Automotive PointPainting

MLPerf es una suite de benchmarks desarrollada por MLCommons para medir el rendimiento de hardware y software en tareas de aprendizaje automático. Se trata de una herramienta estandarizada, abierta y revisada por pares, que permite comparar plataformas de forma justa y reproducible, promoviendo así la innovación y eficiencia en todo el ecosistema de inteligencia artificial. Su enfoque abarca tanto sistemas de datacenter como dispositivos en el borde (edge computing), evaluando distintos tipos de modelos y escenarios reales de uso.

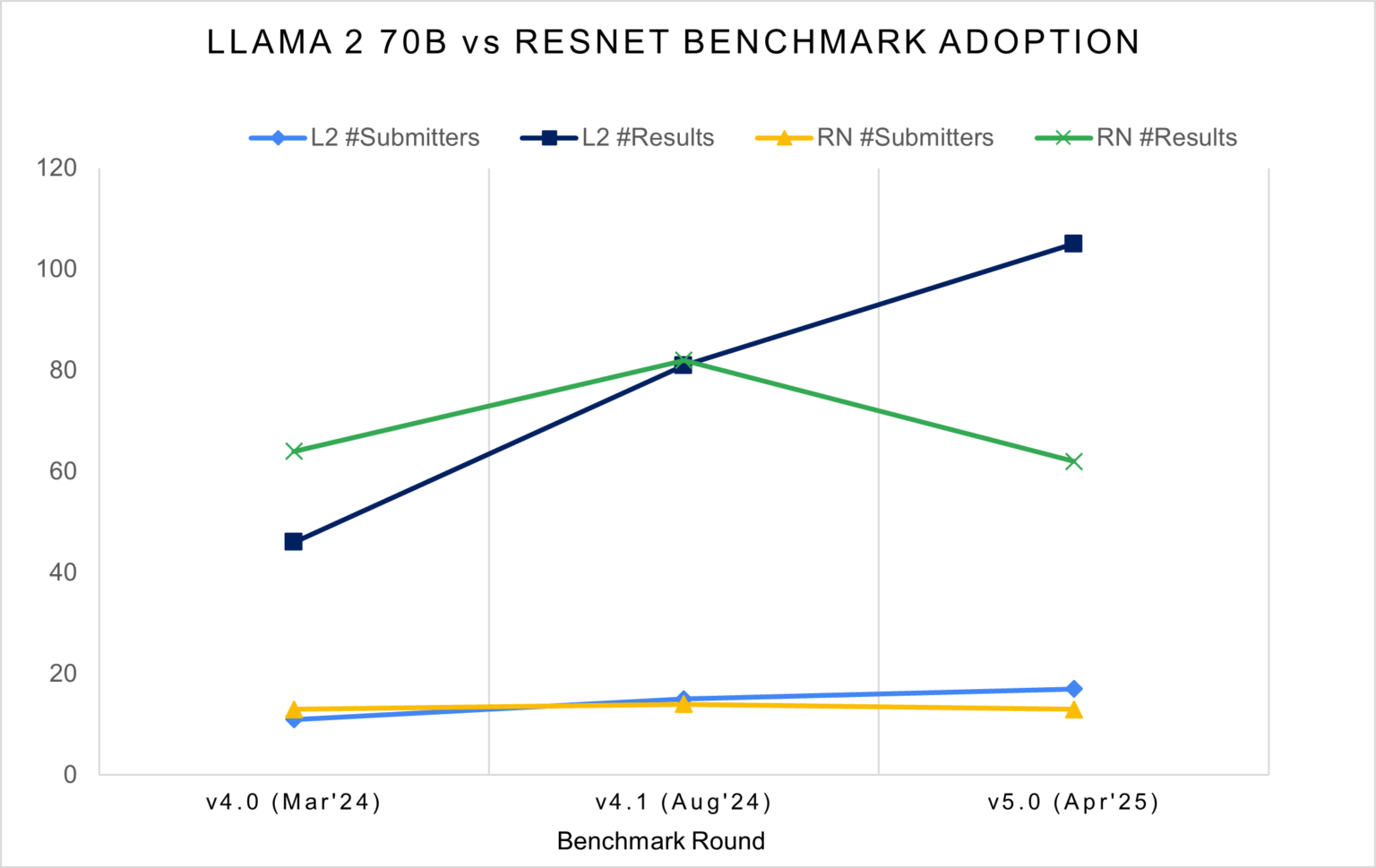
El estudio destaca que hubo un cambio importante en esta edición, detalla que Llama 2 70B es el benchmark más usado, superando a ResNet50. Esto es un claro indicio de que la industria dio un giro en 360º hacia las redes GenAI.
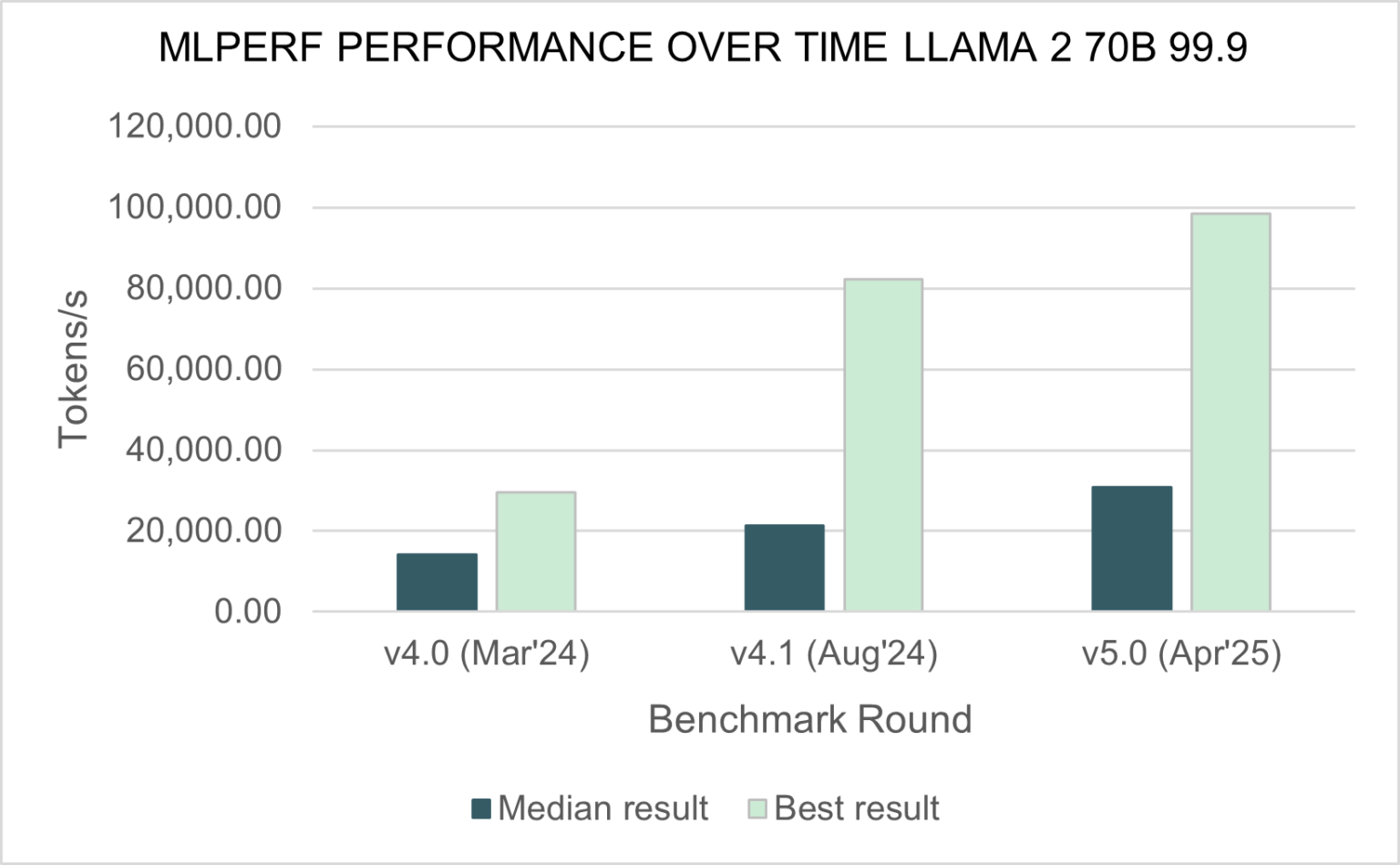
En cuanto al rendimiento, se observan avances considerables. MLCommons, destaca que las métricas de tokens por segundo, detallan que el mejor resultado obtenido con 70B es 3.3 veces superior al de hace un año.
Por otra parte, en cuanto a la mediana, se observa que el rendimiento aumentó 5 veces, destacando un gran progreso en cuanto a la optimización del hardware y software.
David Kanter, director de MLPerf en MLCommons, afirmó:
"Es evidente que gran parte del ecosistema está enfocado en desplegar IA generativa, y que el ciclo de retroalimentación del benchmarking de rendimiento está funcionando. Estamos viendo una avalancha sin precedentes de nuevas generaciones de aceleradores, combinados con técnicas de software alineadas como el soporte al formato de datos FP4".

El estudio destaca que el Intel Xeon 6 es la única CPU de propósito general presente en las pruebas. Esto refuerza el hecho de que el procesador para data centers por excelencia, es una muy buena alternativa eficiente y escalable frente a aceleradores dedicados. Esto aún más crucial, donde es necesario contar con hardware más versátil y compatible con arquitecturas tradicionales.

Karin Eibschitz Segal, vicepresidenta de Intel, afirmó:
"Los últimos resultados de MLPerf demuestran que Intel Xeon 6 es la CPU ideal para cargas de trabajo de IA, ofreciendo un equilibrio perfecto entre rendimiento y eficiencia energética. Intel Xeon sigue siendo la CPU líder para sistemas de IA, con mejoras consistentes generación tras generación".
Uno de los benchmarks más exigentes fue el nuevo Llama 3.1 405B, que elevó la escala de los modelos evaluados con 405 mil millones de parámetros y tareas que incluyen generación de código, matemáticas y preguntas abiertas; sobre esto, Miro Hodak, copresidente del grupo de trabajo MLPerf Inference, señaló que:
"Este es nuestro benchmark de inferencia más ambicioso hasta la fecha. Refleja la tendencia de la industria hacia modelos más grandes, que pueden aumentar la precisión y abarcar un conjunto más amplio de tareas".
Otro modelo que debuta en el benchmark es el Llama 2 70B Interactive, ideado para medir tiempos de respuestas en ecosistemas conversacionales, donde se usan chatbots, con muy baja latencia.
Mitchelle Rasquinha, copresidenta del grupo MLPerf Inference, explicó:
"Una métrica crítica en el rendimiento de un sistema de consulta o chatbot es qué tan rápido responde. Esta versión interactiva del test de Llama 2 70B ofrece nuevas perspectivas sobre el desempeño de los LLMs en escenarios reales".

El benchmark reunió más de 17 mil resultados de rendimiento provenientes de 23 organizaciones, incluyendo Google, AMD, NVIDIA, Cisco, Dell y Supermicro. La inclusión de nuevos actores como Lambda y MangoBoost también marcó un crecimiento del ecosistema, reflejando el interés global por contar con métricas fiables y comparables en un contexto de rápida evolución tecnológica.







{kind=link}